A blog post about our paper, “Re-Centering Humans in LLM Personalization”
TL;DR — Most personalization benchmarks rely on synthetic personas and LLM judges. We collected 550 real user conversations and ~19,000 human judgments across the full personalization pipeline, and found systematic human–LLM gaps at every stage: models extract noisy attributes from real conversations, over-select what’s relevant by 2–3×, and generate “personalized” responses that humans judge no better than generic ones — even as LLM judges rate them highly.
Chatbots increasingly remember things about you — your job, your hobbies, how you like answers formatted — and use them to “personalize” responses. Sometimes that’s genuinely helpful. Sometimes it gives you a computer-themed vacation recommendation because you once mentioned being a software developer.
How would we know whether personalization is actually working? Today, mostly by asking machines. The field’s benchmarks lean heavily on synthetic personas, simulated conversations, and LLM judges scoring LLM outputs. The one party that’s missing is the person being personalized for.
Our paper asks what changes when you put real humans back into the evaluation loop — and the answer is: a lot.

🗺️ Three questions every personalization system must answer
Grounding the framework in prior personalization and memory systems, we decompose personalization into three stages:
- 🧠 Attribute extraction — what should the system infer about you from your conversation history?
- 🎯 Relevance matching — which of those attributes matter for this request?
- ✍️ Response generation — does using them actually improve the response?
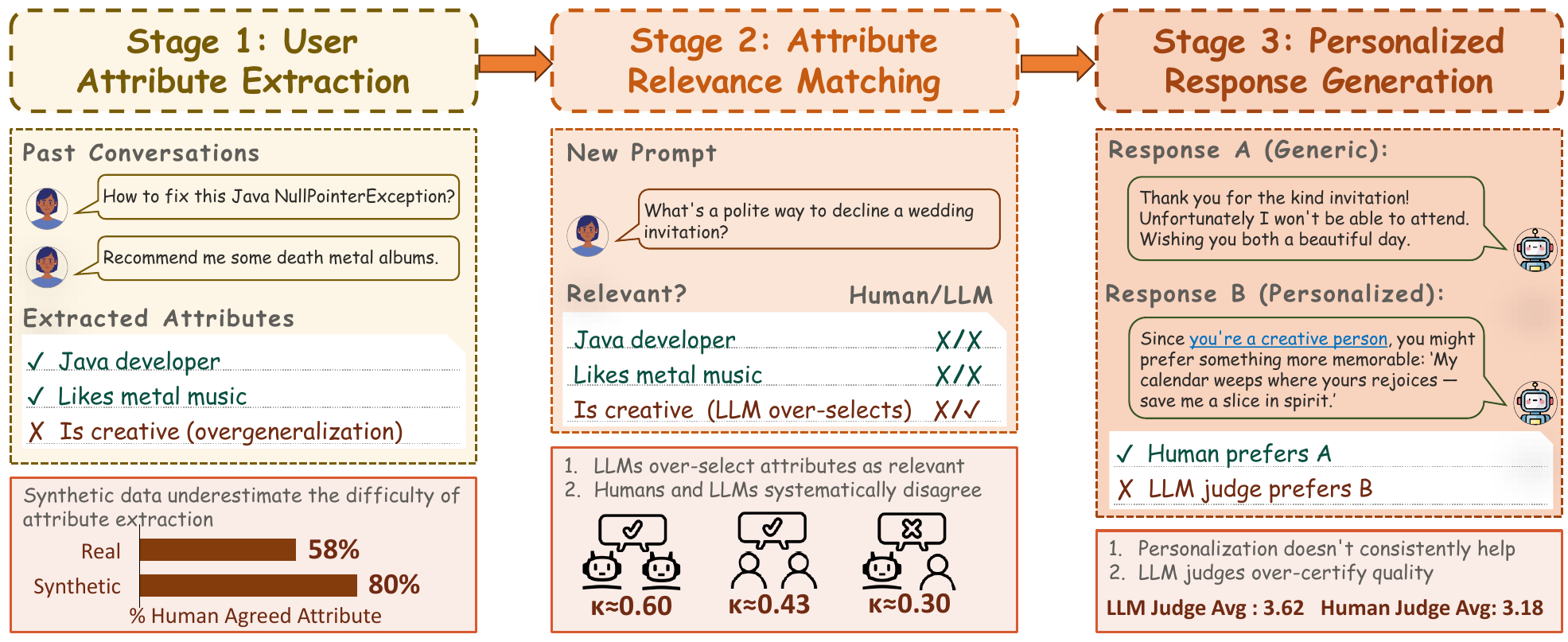 Figure 1: The three-stage personalization pipeline: attribute extraction, relevance matching, and response generation.
Figure 1: The three-stage personalization pipeline: attribute extraction, relevance matching, and response generation.
This decomposition lets us pinpoint where personalization breaks down, rather than treating it as one end-to-end black box.
A note on how we collected human data. Our real-user corpus comes from WildChat: we clustered conversations into per-user histories, filtered out non-English, scripted, and low-activity accounts. For judgments, we recruited annotators on Prolific and get 5,949 attribute-quality judgments, 11,919 relevance judgments, and 1,101 response-preference ratings.
🧠 Stage 1: Synthetic data hides real extraction failures
We ran the same extractor over real (WildChat) and synthetic conversations (3 recent benchmarks) for a controlled comparison, then had annotators label each extracted attribute as accepted, uncertain, or rejected.
🔑 Key finding: extracting attributes that humans find valid is considerably harder from real conversations — synthetic data underestimates the difficulty of this stage. An additional 22% of attributes from real chats were judged problematic.
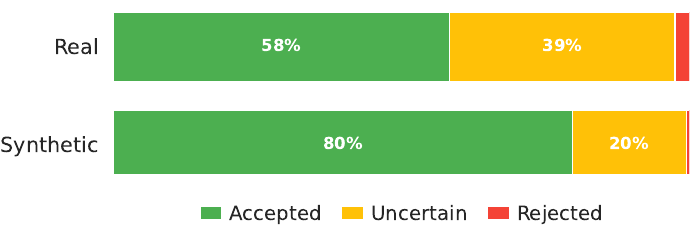 Figure 2: Attribute quality annotation breakdown (accepted / uncertain / rejected) for real vs. synthetic datasets.
Figure 2: Attribute quality annotation breakdown (accepted / uncertain / rejected) for real vs. synthetic datasets.
When we categorized the 1,225 flagged attributes, over half (53.9%) failed due to overgeneralization — one translation request becomes “user is learning French.” Another 16% showed task-context confusion — a fictional cover-letter prompt becomes “user has five years of marketing experience.” These failure modes barely exist in synthetic data, where user traits are clean by construction.
🎯 Stage 2: Models think everything about you is relevant
Now suppose the attributes are correct. Which ones should influence the answer to a new question? We paired our annotated WildChat users from Stage 1 with prompts from LIMA, a high-quality SFT dataset. Each pair was judged independently by all three human annotators and five LLMs under the same instruction: should this attribute change the response in any way, either explicitly or implicitly?
🔑 Key finding: humans and LLMs systematically disagree on relevance — despite each group agreeing internally. Humans reach κ = 0.43 with each other; LLMs agree even more strongly among themselves (κ = 0.60); but human–LLM agreement is only κ = 0.30. LLMs aren’t reliable proxies for human relevance judgment.
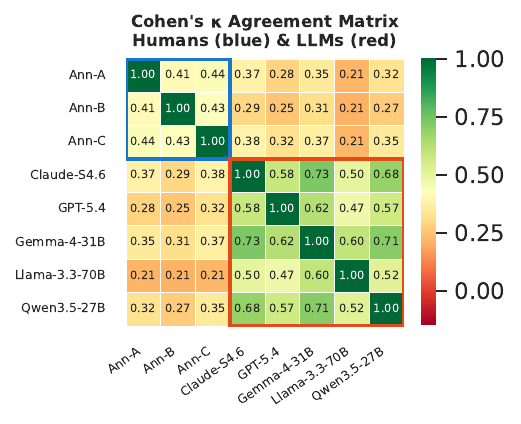 Figure 3: Pairwise Cohen’s κ agreement matrix across human annotators and LLM judges.
Figure 3: Pairwise Cohen’s κ agreement matrix across human annotators and LLM judges.
The disagreement has a clear direction: humans marked only ~20% of attributes as relevant; LLMs marked 40–60%. Models systematically over-personalize, pulling your hobbies into your tax questions. That’s exactly the instinct behind the computer-themed vacation spot.
For downstream evaluation, we use the majority vote of the three annotators as the human-consensus label. Figure 4 compares retrieval baselines and LLM judges against this label.
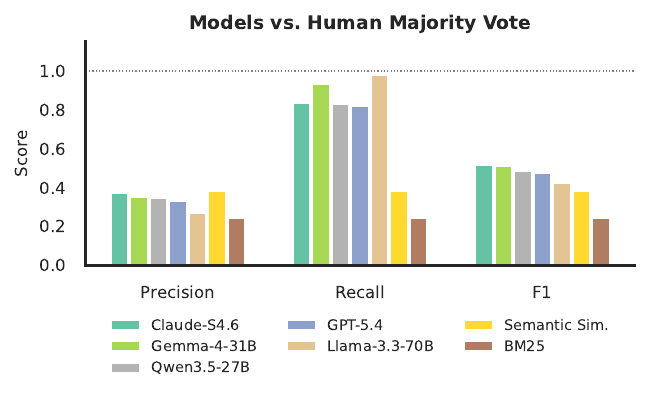 Figure 4: Precision/recall/F1 of retrieval baselines and LLM judges against human-consensus relevance labels.
Figure 4: Precision/recall/F1 of retrieval baselines and LLM judges against human-consensus relevance labels.
🔑 Key finding: LLMs tend to over-personalize by selecting too many attributes as relevant. Humans marked only ~20% of attributes as relevant, while LLMs marked 40–60%. This shows up in Figure 4 as relatively high recall but low precision: models catch many attributes humans consider relevant, but also select many that humans would leave out.
Semantic-similarity methods do even worse: BM25 and embedding retrieval reach only F1 = 0.243 and 0.384, suggesting that relevance is not simply about matching similar words or topics.
✍️ Stage 3: Personalized ≠ better
Finally, the stage everything builds toward. We took the human-majority-voted relevant attributes from Stage 2 — i.e., the best-case input — and had five LLMs generate personalized responses. Human annotators then saw two side-by-side, randomly shuffled responses (one generic, one personalized) and rated their preference on a 5-point scale, attribute by attribute.
🔑 Key finding: personalized responses do not consistently improve response quality for users. 54.6% of personalized responses were judged no better than their generic counterparts. Even GPT-5.4 and Claude barely cleared the neutral baseline, and some open-source models made responses actively worse by personalizing.
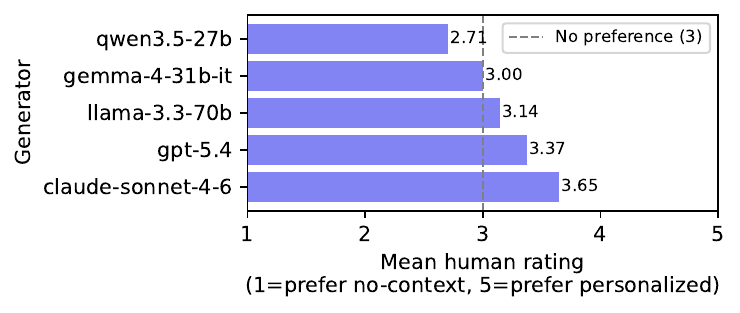 Figure 5: Mean human preference rating for personalized vs. generic responses, broken down by LLM generator.
Figure 5: Mean human preference rating for personalized vs. generic responses, broken down by LLM generator.
🔑 Key finding: LLM judges overestimate personalization quality while only partially aligning with human preferences. Every LLM judge assigned significantly higher average ratings than humans did.
Why the inflation? A big culprit is mechanical attribute invocation — responses that bolt on “Given your interest in machine learning…” without adapting anything substantive. We used GPT-5.4 to flag responses with explicit attribute mentions and measured each judge’s rating gap. Several open-weight judges rewarded explicit mentions; humans showed almost no sensitivity (Δ = 0.03).
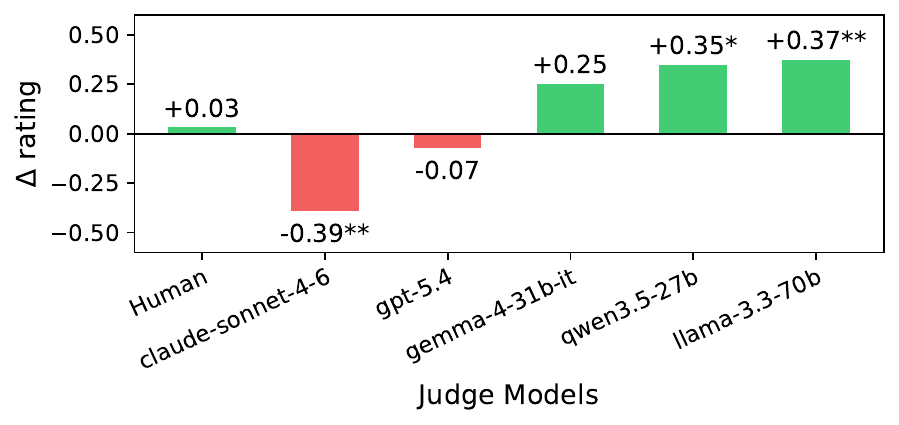 Figure 6: Rating gap between responses with and without explicit attribute mentions, by judge.
Figure 6: Rating gap between responses with and without explicit attribute mentions, by judge.
And here’s our favorite twist: a model’s habits as a generator predict its biases as a judge (Spearman r = 0.90). Models that frequently name-drop your attributes when writing also reward name-dropping when grading. Claude sits at the opposite extreme — it mentions attributes explicitly in only 5% of its responses and is the only judge that significantly penalizes them, more harshly than humans would (Δ = −0.39 vs. human Δ = 0.03). Surface-level personalization preferences appear to carry over from generation to evaluation.
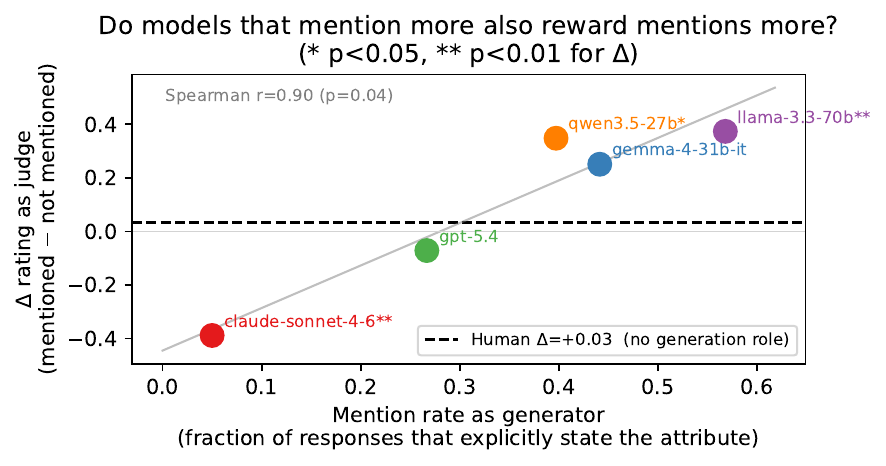 Figure 7: Explicit attribute mention rate as a generator (x-axis) vs. rating uplift for explicit mentions as a judge (y-axis), by model.
Figure 7: Explicit attribute mention rate as a generator (x-axis) vs. rating uplift for explicit mentions as a judge (y-axis), by model.
🛠️ Can training on human data close the gap?
Partly — and that’s encouraging in itself. We tested lightweight, training-based interventions at each stage using our human annotations:
- Stage 1: A small RoBERTa verifier trained on human judgments outperforms every zero-shot frontier model at catching unsupported attributes. Used in a verify-and-refine loop, it raised human acceptance of extracted attributes from 58% to over 90%.
- Stage 2: A GRPO-trained Qwen3-4B reaches F1 = 0.641 against human relevance labels — beating every frontier model (best zero-shot: 0.515) — and learns to reason more cautiously about whether an attribute should matter.
- Stage 3: This one resisted us. Reward models trained on human ratings topped out around ρ ≈ 0.3, no better than the strongest LLM judges.
These results show that human data can meaningfully improve personalization systems, especially for extraction and relevance judgment. But they should not be read as evidence that one universal model can decide what good personalization looks like for everyone. Personalization preference is individual: even our trained annotators only moderately agreed with one another on what counts as good personalization, because reasonable people genuinely want different things. Averaging them into one “human standard” smooths away exactly the variation personalization is supposed to serve. The real goal is user-specific, preference-adaptive systems that take each person seriously rather than fitting one curve to everyone. What we contribute, then, is a starting point: an initial source of real human data and a framework for collecting more of it. We see this as the first step toward modeling individuals seriously — not the last word on how to do it.
🧭 The takeaway
At every stage of the pipeline, swapping synthetic users and LLM judges for real humans exposed problems that current benchmarks hide:
- 🧠 Models extract noisy, overgeneralized attributes from real conversations.
- 🎯 They consider 2–3× more attributes relevant than humans do.
- ✍️ Their personalized outputs are often no better than generic ones — and LLM judges can’t reliably tell.
Modest amounts of human data go a long way toward fixing the first two stages. The third — knowing what actually makes a response better for you — remains open, and probably requires asking you.
📄 Paper: arxiv.org/abs/2606.06614 💻 Code & data: github.com/orange0629/recenter-personalization
Authors: Lechen Zhang, Jiarui Liu, Tal August